
Conventions
Key concepts - you will be responsible for knowing a number of definitions of key concepts. You may be asked to give an accurate definition and example of any of the key concepts. Key concepts are in italics, bolded and colored red throughout the notes.
Discussion questions - the lecture notes contain three discussion questions. These are to be answered on Blackboard at the times given in the syllabus.
Critical points - there are some points that require extra emphasis because they are fundamental to the example or concept being discussed. Critical points are bolded, in italics and colored orange.
Course learning objective questions - These are the questions given in the learning objectives document.
The End of Behaviourism
1) Research Findings
Your text and many others cite Edward Tolman as a figure that was extremely instrumental in advancing the acceptance of hypothetical, mental constructs in the highly positivist, behaviorist era in psychology.
The most commonly cited study of Tolman’s was as follows:
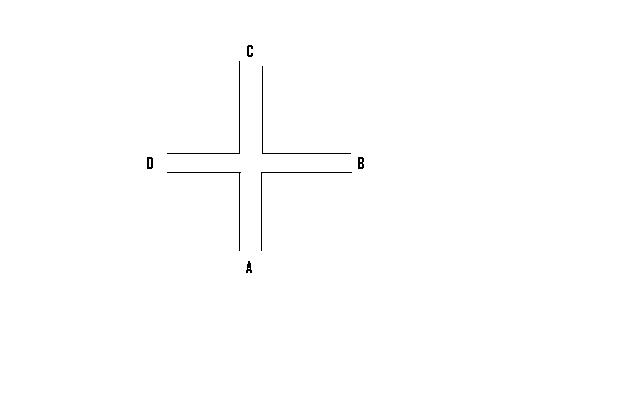
1) A maze was constructed in the shape of a cross. See below.
2) Initially, a rat was started at position A in the maze and quickly found the food that was located at position B.
3) The behaviorist explanation for this is that the rat learned a specific response to the stimulus of the maze and food and that the response was “turn right”.
4) However, in the second part of the experiment, the same rats were started at position C. If the rats had learned “turn right”, then we would expect the rats to go quickly to position D.
5) Tolman found that the rats did not turn right. They immediately turned left. This could not be explained using behaviorist stimulus-response theory.
6) Tolman’s explanation was decidedly against the behaviorist tradition. He explained the rat’s behavior by using a hypothetical, mental construct. He suggested that the rats had a cognitive map of the maze. The rat turned left because it had formed a mental map of the maze and knew where the food was in relation to various starting points.
Findings such as this became one of the principle justifications for modern cognitive psychology. The view was that hypothetical mental entities should be used to explain animal and human behavior.
Now, the idea that theoretical or hypothetical constructs should be part of science is consistent with a view called scientific realism. So in the mid 1950’s, psychology began to adopt scientific realism.
Scientific realism allowed psychologists to invoke hypothetical constructs. So such concepts as mental representation, information processing, mental structures, etc, began to creep back in to psychology. As psychology accepted realism it grew and gained social relevance dramatically. It became clear that realism offered to psychologists a new hope of relevance, influence and power.
Although realism does allow for the existence of hypotheses and theories about unobservable, hypothetical entities, it only allows for them as part of a causal explanation of observed events. In realism, the scientific problem is to define these unobservable, hypothetical entities carefully and show how they could be responsible for patterns of observed empirical events. For example, to the realist, it is perfectly acceptable to hypothesize that an as yet, unobserved, but very well defined neural structure called schizoneuronalism causes schizophrenia.
In physics, for example, the realist holds that it is perfectly acceptable to invoke concepts such as the “big bang” to explain or account for the expansion of the universe, even though the big bang event has not and could never be observed. Today, physicists hypothesize that the big bang is an event that occurred at the beginning of time. Now, the big bang is very well defined, it is just something that we have not observed (and could not observe because it happened 15 billion years ago). Its role in physics is as a causal explanation of two things that have been directly observed:
1) The expansion of the universe
2) A certain type of background radiation
So, it is reasonable to say that most physical scientists today are scientific realists, not hard-nosed positivists. I would say that most of the physical scientists that I have worked with are willing to allow hypothetical constructs but they don't realish them much. They treat them as a useful, sometimes necessary evils.
I think the story of the "discovery" of the big bang is very instructive in this respect. Let's look at it.
In 1964 Arno Penzias and Robert Wilson used a supersensitive horn antenna built by Bell (as in Bell telephone) labs to measure background radio waves. They expected to measure very few radiation waves at the frequency they were looking in but found 100 times more than was supposed to be there. After many long months of arduous effort trying to determine what was wrong with the antenna, they finally came to the conclusion that nothing was wrong with the antenna and the background radiation waves were actually there. The link below takes you to an audiotape where you can hear the unexpected "noise" they discovered.
http://www.npr.org/templates/story/story.php?storyId=4655517
Now, about the same time time, Robert Dicke, Jim Peebles and David Wilkinson from Princeton University predicted that a "big bang" cosmic event could cause a certain type and amount of background radio waves.
Penzia and Wislon became aware of this prediction and immediately relaized that the radiation waves they had found were the radiation waves that had been precietd to exist by the Princeton team.
In the end, both sets of astrophysicists wrote papers about their findings and published them in the same edition of the journal Astrophysical Letters.
Now, who do you think won the Nobel prize? The guys that predicted the big bang and said exactly what we should see if a big bang event did happen, or the guys that found some radio waves that they could not explain and had no idea should be there.
The Noble prize was awarded to Penzias and Wilson, not the guys that predicted the radiation that Penzias and Wislon found. Now, my take on this is that Penzias and Wilson's discovery was a discovey of something directly observable. It was a result of extremely detailed and careful measurement of something that others could also observe and verify. The Pinceton team, however, did'nt really observe anything. They explained something but did not observe anyhting. To me, this is an indication that hypothetical/theoretical causal explanations like the big bang are not massively respected in the phyical sciences. Yes they exist, but they are'nt really seen as the cornerstone of science. So although modern physics is realist, they still have positivist leanings. They still respect careful observation over theoretical explanations.
Now, let's get back to the motivation for psychology to change from the positivist, operationist, behaviorsit era to the new, modern era of psychology.
2) Construct Validity Theory
Construct validity theory was an invention of two men: Lee Cronbach and Paul Meehl. The following is a series of excerpts from the paper in which they introduced construct validation to psychology. Read it carefully and then read through my summary of their position. The full paper is available on the “Classics in the History of Psychology” website at: http://psychclassics.asu.edu/Cronbach/construct.htm.
CONSTRUCT VALIDITY IN PSYCHOLOGICAL TESTS
Lee J. Cronbach and Paul E. Meehl (1955)
Selected Sections With Instructor Comments
First published in Psychological Bulletin, 52, 281-302.
My comments in orange, critical sections in red.
Validation of psychological tests has not yet been adequately conceptualized, as the APA Committee on Psychological Tests learned when it undertook (1950-54) to specify what qualities should be investigated before a test is published. In order to make coherent recommendations the Committee found it necessary to distinguish four types of validity, established by different types of research and requiring different interpretation. The chief innovation in the Committee's report was the term construct validity. This idea was first formulated by a subcommittee (Meehl and R. C. Challman) studying how proposed recommendations would apply to projective techniques, and later modified and clarified by the entire Committee (Bordin, Challman, Conrad, Humphreys, Super, and the present writers). The statements agreed upon by the Committee (and by committees of two other associations) were published in the Technical Recommendations. The present interpretation of construct validity is not "official" and deals with some areas where the Committee would probably not be unanimous. The present writers are solely responsible for this attempt to explain the concept and elaborate its implications.
The Technical recommendations is a 200 page document detailing exactly how psychological tests must be developed and used. It states the standards that psychologists must adhere to in the development of tests to measure psychological constructs (e.g., intelligence, depression, clinical depression, ADHD, anxiety, etc.). Here is the URL to the website for "The Reccomendations": http://teststandards.org/index.htm.
FOUR TYPES OF VALIDATION
The categories into which the Recommendations divide validity studies are: predictive validity, concurrent validity, content validity, and construct validity. The first two of these may be considered together as criterion-oriented validation procedures.
The pattern of a criterion-oriented study is familiar. The investigator is primarily interested in some criterion which he wishes to predict. He administers the test, obtains an independent criterion measure on the same subjects, and computes a correlation. If the criterion is obtained some time after the test is given, he is studying predictive validity. If the test score and criterion score are determined at essentially the same time, he is studying concurrent validity. Concurrent validity is studied when one test is proposed as a substitute for another (for example, when a multiple-choice form of spelling test is substituted for taking dictation), or a test is shown to correlate with some contemporary criterion (e.g., psychiatric diagnosis).
For example, if we are using high-school GPA to predict University GPA, we are interested in the predictive validity of high-school GPA as a measure of the criterion which is University GPA.
For example, if we are using the diameter of a tree to estimate the height of a tree, we are interested in the concurrent validity of diameter of the tree as a measure of the height of a tree.
Content validity is established by showing that the test items are a sample of a universe in which the investigator is interested. Content validity is ordinarily to be established deductively, by defining a universe of items and sampling systematically within this universe to establish the test.
For example, if I were to give a midterm exam on chapters 1-7 in the text and I selected 10 questions from each chapter; my test would have content validity as a measure of chapters 1-7. However, if I selected 90 questions from chapter 1 and 10 questions from the remaining 6 chapters, my test would not have content validity as a measure of chapters 1-7.
Construct validation is involved whenever a test is to be interpreted as a measure of some attribute or quality which is not "operationally defined." The problem faced by the investigator is, "What constructs account for variance in test performance?" Construct validity is not to be identified solely by particular investigative procedures, but by the orientation of the investigator. Criterion-oriented validity, as Bechtoldt emphasizes, "involves the acceptance of a set of operations as an adequate definition of whatever is to be measured." (This is the operational definition. The operational definition is the definition of the criterion.) When an investigator believes that no criterion available to him is fully valid, he perforce becomes interested in construct validity because this is the only way to avoid the "infinite frustration" of relating every criterion to some more ultimate standard. Construct validity is ordinarily studied when the tester has no definite criterion measure of the quality with which he is concerned, and must use indirect measures. Here the trait or quality underlying the test is of central importance, rather than either the test behavior or the scores on the criteria.
THE RELATION OF CONSTRUCTS TO "CRITERIA"
An unquestionable criterion may be established as a consequence of an operational definition. Typically, however, the psychologist is unwilling to use the directly operational approach because he is interested in building theory about a generalized construct. A theorist trying to relate behavior to "hunger" almost certainly invests that term with meanings other than the operation "elapsed-time-since-feeding." If he is concerned with hunger as a tissue need, he will not accept time lapse as equivalent to his construct because it fails to consider, among other things, energy expenditure of the animal.
For example, Skinner would have said that a hungry pigeon is defined as 2/3rd's of normal body weight. This would be the operational definition of hunger. But to the CV theorist, this idea denies the construct of hunger it's very meaning. Hunger is not actually 2/3rd's of body weight and so it makes no sense to measure hunger this way. The CV theorist is interested in hunger and so they need a way to measure it. The idea is that they can not do this directly (because hunger is a hypothetical construct....it is not directly AND publicly observable) so they must measure hunger indirectly. To do this, they must develop a test to measure hunger and then use construct validity procedures to establish that the test is a valid measure of hunger.
INADEQUACY OF VALIDATION IN TERMS OF SPECIFIC CRITERIA
The proposal to validate constructual interpretations of tests runs counter to suggestions of some others. Spiker and McCandless favor an operational approach. Validation is replaced by compiling statements as to how strongly the test predicts other observed variables of interest. To avoid requiring that each new variable be investigated completely by itself, they allow two variables to collapse into one whenever the properties of the operationally defined measures are the same: "If a new test is demonstrated to predict the scores on an older, well-established test, then an evaluation of the predictive power of the older test may be used for the new one." But accurate inferences are possible only if the two tests correlate so highly that there is negligible reliable variance in either test, independent of the other. Where the correspondence is less close, one must either retain all the separate variables operationally defined or embark on construct validation.
The operational approach described here involves correlating criteria with each other. This means establishing the predictive or concurrent validity of criteria. If we want to estimate the height of a tree, we can use the diameter. But if the height of a tree is not VERY STRONGLY correlated with the diameter, we must retain both measures. We can not substitute one for the other OR suggest we are measuring something more general such as the size of the tree with each measure.
The practical user of tests must rely on constructs of some generality (for instance, the size of a tree is a more general measure than height or diameter) to make predictions about new situations. Test X could be used to predict palmar sweating in the face of failure without invoking any construct, but a counselor is more likely to be asked to forecast behavior in diverse or even unique situations for which the correlation of test X is unknown. Significant predictions rely on knowledge accumulated around the generalized construct of anxiety. The Technical Recommendations state:
It is ordinarily necessary to evaluate construct validity by integrating evidence from many different sources. The problem of construct validation becomes especially acute in the clinical field since for many of the constructs dealt with it is not a question of finding an imperfect criterion but of finding any criterion at all. The psychologist interested in construct validity for clinical devices is concerned with making an estimate of a hypothetical internal process, factor, system, structure, or state and cannot expect to find a clear unitary behavioral criterion. An attempt to identify any one criterion measure or any composite as the criterion aimed at is, however, usually unwarranted.
There is no single behavioral measure of depression. The construct is more complex, multifaceted, multi-determined, etc., than this. This means that the clinical psychologist must find some way to measure depression that respects this complexity. This is why the DSM approach is viewed skeptically by many CV Theorists. They don't think a simple, operational style definition of depression can be given, as is attempted in DSM.
This appears to conflict with arguments for specific criteria prominent at places in the testing literature. Thus Anastasi makes many statements of the latter character: "It is only as a measure of a specifically defined criterion that a test can be objectively validated at all . . . To claim that a test measures anything over and above its criterion is pure speculation". (This is positivism. This is the idea that we should not speculate about what something is or what a test measures. In Watson's words, this is just medieval speculation.) Yet elsewhere this article supports construct validation. Tests can be profitably interpreted if we "know the relationships between the tested behavior . . . and other behavior samples, none of these behavior samples necessarily occupying the preeminent position of a criterion". Factor analysis with several partial criteria might be used to study whether a test measures a postulated "general learning ability." If the data demonstrate specificity of ability instead, such specificity is "useful in its own right in advancing our knowledge of behavior; it should not be construed as a weakness of the tests".
We depart from Anastasi at two points. She writes, "The validity of a psychological test should not be confused with an analysis of the factors which determine the behavior under consideration." (This means...the question of what a test measures should not be confused with what causes the behavior the test measures). We, however, regard such analysis as a most important type of validation (So, in CV theory then, what causes the behaviour the test measures tells us something about what the test measures). Second, she refers to "the will-o'-the-wisp of psychological processes which are distinct from performance". While we agree that psychological processes are elusive, we are sympathetic to attempts to formulate and clarify constructs which are evidenced by performance but distinct from it. Surely an inductive inference based on a pattern of correlations cannot be dismissed as "pure speculation.". (This inductive inference referred to here IS what I have called inductive definition. This means we can hypothesize about what a test measures based upon what factor the test correlates with. We can hypothesize that a pen and paper test of depression measures a physiological abnormality of the brain if scores on the test are correlated with fmri scan results.)
EXPERIMENTATION TO INVESTIGATE CONSTRUCT VALIDITY
Validation Procedures
We can use many methods in construct validation. Attention should particularly be drawn to Macfarlane's survey of these methods as they apply to projective devices.
Group differences. If our understanding of a construct leads us to expect two groups to differ on the test, this expectation may be tested directly. Thus Thurstone and Chave validated the Scale for Measuring Attitude Toward the Church by showing score differences between church members and nonchurchgoers. Churchgoing is not the criterion of attitude, for the purpose of the test is to measure something other than the crude sociological fact of church attendance (to measure attitudes towards the church that is.); on the other hand, failure to find a difference would have seriously challenged the test.
Only coarse correspondence between test and group designation is expected. Too great a correspondence between the two would indicate that the test is to some degree invalid, because members of the groups are expected to overlap on the test (This just means that if the test distinguishes perfectly between churchgoers and nonchurchgoers then all the test measures is church attendance not some underlying attitude towards the church.).
This is an excellent example of the CV logic.
Hypothesize that the test is a measure of the construct “attitude towards the church”. Theorize that if the test is a measure of attitudes towards the church scores should be somewhat different for churchgoers than non churchgoers (if the scores were very different then we would conclude that the test measures church attendance and not attitudes towards the church) Conduct the experiment. If the scores are somewhat different, this is evidence that the test measures attitudes towards the church. If the scores are not somewhat different conclude: a) the test does not measure attitudes towards the church, or b) the theory that attitude towards the church is related to church attendance is incorrect.
Correlation matrices and factor analysis. If two tests are presumed to measure the same construct, a correlation between them is predicted. If the obtained correlation departs from the expectation, however, there is no way to know whether the fault lies in test A, test B, or the formulation of the construct. A matrix of intercorrelations often points out profitable ways of dividing the construct into more meaningful parts, factor analysis being a useful computational method in such studies.
Guilford (26) has discussed the place of factor analysis in construct validation. His statements may be extracted as follows:
"The personnel psychologist wishes to know 'why his tests are valid.' He can place tests and practical criteria in a matrix and factor it to identify 'real dimensions of human personality.' A factorial description is exact and stable; it is economical in explanation; it leads to the creation of pure tests which can be combined to predict complex behaviors."
It is clear that factors here function as constructs. Eysenck, in his "criterion analysis", goes farther than Guilford, and shows that factoring can be used explicitly to test hypotheses about constructs.
So a factor is a real dimension of human personality here. This is so important historically. This is when the factor analysis procedure really took off in psychology. Now, a factor is a mathematical construction. It is one of the outputs of a mathematical model that has been fit to a set of test scores or responses to test items. The idea here is that the factor represents something real, beyond the actual factor itself. That is, the factor represents some construct that the test is measuring.
Now, C & M are saying that we may want to give the factor additional meanings beyond that of “a dimension that the tests or items measure”. This is the age old "what is it" question. “What is the factor”? What is “the underlying construct that the items or tests measure?” The method of determining what the factor really is is to construct and test theories about what it is. So we theorize that the factor is, for example, “attitudes towards the church” and test this theory by correlating church attendance with scores on the factor.
Studies of internal structure. For many constructs, evidence of homogeneity within the test is relevant in judging validity. If a trait such as dominance is hypothesized, and the items inquire about behaviors subsumed under this label, then the hypothesis appears to require that these items be generally intercorrelated. Even low correlations, if consistent, would support the argument that people may be fruitfully described in terms of a generalized tendency to dominate or not dominate.
So if we have 20 questions that we hypothesize measure attitudes towards the church (e.g., 1) How often do you pray, 2) Do you believe in God, 3) Do you own a picture of the pope, etc.), the idea is that responses to these questions should be positively correlated with each other (i.e., If you have a picture of the pope then you should also believe in God and pray often.).
Studies of change over occasions. The stability of test scores ("retest reliability," Cattell's "N-technique") may be relevant to construct validation. Whether a high degree of stability is encouraging or discouraging for the proposed interpretation depends upon the theory defining the construct
We have a theory about what anxiety is. This theory defines what anxiety is. This is EXACTLY Aristotle’s logic. He has a theory about how the soul should be defined. REMEMBER THOUGH that Aristotle tested his theory using logical argument. This is the method of metaphysics. In CV theory, this is unacceptable. Theories about what things are must be tested with empirical research. Perhaps by collecting responses to measures about attitudes towards the church and deteremining what factors the test scores correlate with.
Studies of process. One of the best ways of determining informally what accounts for variability on a test is the observation of the person's process of performance. If it is supposed, for example, that a test measures mathematical competence, and yet observation of students' errors shows that erroneous reading of the question is common, the implications of a low score are altered. Lucas in this way showed that the Navy Relative Movement Test, an aptitude test, actually involved two different abilities: spatial visualization and mathematical reasoning.
Mathematical analysis of scoring procedures may provide important negative evidence on construct validity. A recent analysis of "empathy" tests is perhaps worth citing. "Empathy" has been operationally defined in many studies by the ability of a judge to predict what responses will be given on some questionnaire by a subject he has observed briefly. A mathematical argument has shown, however, that the scores depend on several attributes of the judge which enter into his perception of any individual, and that they therefore cannot be interpreted as evidence of his ability to interpret cues offered by particular others, or his intuition.
The procedures described above constitute a very large part of modern psychology. In any instance where measurement of a construct is involved, we see the application of CV procedures and the logic of CV. This involves much of applied psychology, practically all modern personality research, intelligence research, emotion measurement, abnormal psychology, and psychometrics. It is also important to understand that this style of thinking has permeated the discipline so that all undergraduates are now taught to think and work this way. For example, you have been taught to think that addiction is an underlying disorder. This underlying factor is not currently directly observable but may be neurologically or genetically measurable. In part then, the purpose of research is to discover what these factors are and in so doing discover what addiction really is.
The next part of the paper makes aspects of this logic explicit. Please read it very carefully. I will require that you know this logic perfectly because it represents the culmination of 2500 years of philosophizing about the philosophical foundations of our discipline. To understand this logic is to fully understand how psychologists think and work today.
THE LOGIC OF CONSTRUCT VALIDATION
Construct validation takes place when an investigator believes that his instrument reflects a particular construct, to which are attached certain meanings. The proposed interpretation generates specific testable hypotheses, which are a means of confirming or disconfirming the claim. The philosophy of science which we believe does most justice to actual scientific practice will not be briefly and dogmatically set forth. Readers interested in further study of the philosophical underpinning are referred to the works by Braithwaite, Carnap, Pap, Sellars, Feigl, Beck, Kneale, Hempel.
The fundamental principles are these:
1. Scientifically speaking, to "make clear what something is" means to set forth the laws in which it occurs. We shall refer to the interlocking system of laws which constitute a theory as a nomological network.
So the problem is what is it and the method is to develop and test a theory about what it is. The theory is called the nomological (meaning “naming”) network of research findings.
2. The laws in a nomological network may relate (a) observable properties or quantities to each other; or (b) theoretical constructs to observables; or (c) different theoretical constructs to one another. These "laws" may be statistical or deterministic.
This is the influence of scientific realism here. Theoretical constructs are just hypothetical constructs. They refer to things that have not been observed but are used as causal explanations of things we do observe….Why does the rock fall? Gravity makes it fall. Why do people recall only 7 distinct letters? Because they have a short term memory function in the mind/brain.
3. A necessary condition for a construct to be scientifically admissible is that it occur in a nomological net, at least some of whose laws involve observables.
Unobservable phenomena are allowed in science but not everything can be unobservable...otherwise we would be engaged in pure metaphysical speculation. So it's only science if we are observing at least something!
4. "Learning more about" a theoretical construct is a matter of elaborating the nomological network in which it occurs, or of increasing the definiteness of the components. At least in the early history of a construct the network will be limited, and the construct will as yet have few connections.
What something is, is given by a theory about what it is. The more we elaborate and develop the theory, the more we know what it is. Initially, when the theory is in its early stages we only have a vague idea of what the thing is. For instance, we have a number of competing theories about what intelligence is. Further scientific investigation will help us narrow down these theories to one final theory. Once we have this theory, we will know exactly what intelligence is.
5. An enrichment of the net such as adding a construct or a relation to theory is justified if it generates nomologicals that are confirmed by observation or if it reduces the number of nomologicals required to predict the same observations. When observations will not fit into the network as it stands, the scientist has a certain freedom in selecting where to modify the network. That is, there may be alternative constructs or ways of organizing the net which for the time being are equally defensible.
6. We can say that "operations" which are qualitatively very different "overlap" or "measure the same thing" if their positions in the nomological net tie them to the same construct variable..
So, what a test measures is given by what it correlates with (C & M use “position in the nomological net” to mean roughly what the construct correlates with.)
Vagueness of present psychological laws. The idealized picture is one of a tidy set of postulates which jointly entail the desired theorems; since some of the theorems are coordinated to the observation base, the system constitutes an implicit definition of the theoretical primitives and gives them an indirect empirical meaning.
This is very fancy language for something simple. Theoretical primitives are constructs – e.g., anxiety. Constructs get their meaning from the nomological network of empirical findings and theory (E.g., what anxiety is is determined by every single research finding that has ever been made about anxiety). Often, this network is messy in the sense that there are inconsistent or incomplete findings or numerous competing theories. Just look at the state of intelligence research as described in your 1200 text. We have 3 dimensional theories of intelligence, 1 dimensional theories, 9 dimensional theories, we have emotional intelligence we have intelligence as a thing in the brain, intelligence as a concept and so on. This is a great example of the messiness
Psychology works with crude, half-explicit formulations. Nevertheless, the sketch of a network is there; if it were not, we would not be saying anything intelligible about our constructs. We do not have the rigorous implicit definitions of formal calculi (which still, be it noted, usually permit of a multiplicity of interpretations). Yet the vague, avowedly incomplete network still gives the constructs whatever meaning they do have. When the network is very incomplete, having many strands missing entirely and some constructs tied in only by tenuous threads, then the "implicit definition" of these constructs is disturbingly loose; one might say that the meaning of the constructs is underdetermined. Since the meaning of theoretical constructs is set forth by stating the laws in which they occur, our incomplete knowledge of the laws of nature produces a vagueness in our constructs. We will be able to say "what anxiety is" when we know all of the laws involving it; meanwhile, since we are in the process of discovering these laws, we do not yet know precisely what anxiety is.
RECAPITULATION
Construct validation was introduced in order to specify types of research required in developing tests for which the conventional views on validation are inappropriate. Personality tests, and some tests of ability, are interpreted in terms of attributes for which there is no adequate criterion (i.e., no operational definition). This paper indicates what sorts of evidence can substantiate such an interpretation, and how such evidence is to be interpreted. The following points made in the discussion are particularly significant.
1. A construct is defined implicitly by a network of associations in which it occurs. Constructs employed at different stages of research vary in definiteness.
By now you should see what C & M are saying here clearly. The method of definition – answering the “what is it” question – is to construct and empirically test theories about what the test measures and hence, what it is.
2. Construct validation is possible only when some of the statements in the network lead to predicted relations among observables. While some observables may be regarded as "criteria," the construct validity of the criteria themselves is regarded as under investigation.
In CV, even if you have criteria, they aren’t really criteria! What C & M are saying is that even if you define a “glerk” to be a fir tree less than 50 meters tall, you have no evidence for this definition and, hence, it is scientifically questionable. Meaning is a matter of discovery in CV. In CV, we discover the meaning of things; we do not lay meaning down like we do in operationism This is why there is a requirement in the development of the DSM that diagnostic categories must be based on research. It is not admissible to a CV theorist to simply make up categories as an operationist would. We must have some evidence showing that people that fall in to our category are disordered in some way (i.e., they are not doing well at work or school, they suffer from other related conditions such as depression or anxiety, etc.)
3. The network defining the construct, and the derivation leading to the predicted observation, must be reasonably explicit so that validating evidence may be properly interpreted.
In CV, you have to make verifiable predictions about how the test should perform. You can’t hypothesize that the id is responsible for sexual aggression and not provide testable predictions about how the test you use to measure the id should perform if the id does, in fact, exist.
4. Many types of evidence are relevant to construct validity, including content validity, interitem correlations, intertest correlations, test-"criterion" correlations, studies of stability over time, and stability under experimental intervention. High correlations and high stability may constitute either favorable or unfavorable evidence for the proposed interpretation, depending on the theory surrounding the construct.
5. When a predicted relation fails to occur, the fault may lie in the proposed interpretation of the test or in the network. Altering the network so that it can cope with the new observations is, in effect, redefining the construct. Any such new interpretation of the test must be validated by a fresh body of data before being advanced publicly. Great care is required to avoid substituting a posteriori rationalizations for proper validation.
6. Construct validity cannot generally be expressed in the form of a single simple coefficient. The data often permit one to establish upper and lower bounds for the proportion of test variance which can be attributed to the construct. The integration of diverse data into a proper interpretation cannot be an entirely quantitative process.
7. Constructs may vary in nature from those very close to "pure description" (involving little more than extrapolation of relations among observation-variables) to highly theoretical constructs involving hypothesized entities and processes, or making identifications with constructs of other sciences.
8. The investigation of a test's construct validity is not essentially different from the general scientific procedures for developing and confirming theories.
True BUT, BUT, BUT, the theory that is being confirmed in CV theory is a THEORY ABOUT WHAT SOMETHING IS. Operationists would say that these ARE NOT SCIENTIFIC THEORIES. An operationist would say that theories about what something is are PHILOSOPHICAL THEORIES. They would say it makes NO SENSE to theorize about what something is. They would say a SCIENTIFIC THEORY is a theory about what CAUSES something to happen, why something is RELATED to something else, how to TREAT something, but NOT what something is. So Cronbach and Meehl are suggesting we apply the same logic we use to test scientific theories to testing theories about what something is. This is where the disagreement between the operationist and CV theorist lies.
Without in the least advocating construct validity as preferable to the other three kinds (concurrent, predictive, content), we do believe it imperative that psychologists make a place for it in their methodological thinking, so that its rationale, its scientific legitimacy, and its dangers may become explicit and familiar. This would be preferable to the widespread current tendency to engage in what actually amounts to construct validation research and use of constructs in practical testing, while talking an "operational" methodology which, if adopted, would force research into a mold it does not fit.
Interestingly, C&M finish with a pretty clear statement that CV and operationism are incompatible. They are also clear that one current (i.e., 1950’s) problem in psychology is doing CV but thinking like an operationist. This problem still exists.
Some examples From Your Psychology 1200 Text
Below, I have listed a series of critical principles of CV theory. Below each principle is an example of that principle taken from your Psychology 1200 text book.
1) What something is is given by research findings about it. Therefore, it is possible to discover what things are.
Example from your psych 1200 text:
"The neurological approach to understanding intelligence is currently in its heyday. Will this new research reduce what we now call the g-factor to simple measures of underlying brain activity? Or are these efforts totally wrongheaded because what we call intelligence is not a single general mental trait but several culturally adaptive skills? The controversies surrounding the nature of intelligence are a long way from resolution."
Here, the text argues that research is going to reveal to us what intelligence is - the nature of intelligence. We are going to discover what intelligence is.
2) It makes sense to construct and empirically test theories about what something is.
Example: look again at the quotation above from you 1200 text.
Here the text advances the theory that what intelligence really is, is some form of underlying brain activity. But notice that the theory has competitors. We are unsure about this theory because we don’t really know what intelligence is. We don’t know whether it is one ability (g) or several abilities. For instance, the text describes Spearman’s g hypothesis that intelligence is unitary. It also describes Gardner’s theory of 9 intelligences. The text says:
“Gardener argues that we do not have an intelligence, but instead have multiple intelligences….”
How do we decide which theory is correct? We attempt to discover whether intelligence is one dimensional or multi-dimensional by empirically testing our theory using methods like factor analysis, etc.
3) Because of “1” and “2” above, when we do not know much about it, we do not know much about what it is. Hence, early in scientific research, when we do not know much about something, we do not know what it is.
Example: From the same quotation above:
“The controversies surrounding the nature of intelligence are a long way from resolution.”
4) A theory about what something is is essentially a working definition of what it is. Definition and theory are one in the same.
Example: In the chapter on intelligence, there is a heading that says “Contemporary Intelligence Theories”. The first sentence under this heading is:
“Since the mid-1980’s some psychologists have sought to extend the definition of intelligence beyond academic smarts.”
In this quotation we see that the text does not distinguish between theories of intelligence and definitions of intelligence.
5) Science allows for competing theoretical formulations. We do not all have to adopt the same theory about what something is. Different scientists can have different competing theories about what something is and this is fine.
Example from your psych 1200 text:
“We use the term intelligence as though we all agree what it means. We don’t. Psychologists debate whether we should define it as an inherent mental capacity, an achieved level of intellectual performance or an ascribed quality, that, like beauty, is in the eye of the beholder.”
Notice the part about "beauty being in the eye of the beholder". Where does that idea come from? Remember the Sophists? This is just the old idea that what beauty is is different for each of us. Recall from lecture 2:
"In the pre-Socratic era people known as the Sophists argued that there is no such thing as universal truth. The idea was that what ever is true is simply true for a given individual at a given time. In this view, what beauty is for example would have been a pure matter of personal truth. What beauty is to one person might be very different to what it is to another. What beauty is at one point in time would have been different to what it is at another point in time. What beauty is would also perhaps have been seen to be culturally or ethnically dependent."